
やるべき!セマンティックWEBのためのWebサイト構造化データのマークアップ
HTML5でコーディングする方などは「HTMLの構造化」を意識していると思うのですが、さらに検索エンジンフレンドリーというか、クローラーフレンドリーになるためには「構造化データ」をマークアップしていくことが必須です。
「HTMLの構造化」と「構造化データ」は、実は全くの別物で。。
前者はただのコーディングと言って差し支えないと思うのですが、後者にあたってはサイトコンテンツを正確に伝達するための重要な儀式となってくることでしょう。
検索上位に上るかどうかとは関係ないのですが、ユーザーにとって有益な情報と捉えてもらうためにも「SEO」の延長線上としての施策ということになります。
Contents
セマンティックWEBとは。
セマンティックWebとは、Webサイトが持つ意味をコンピュータに理解させ、コンピュータ同士で処理を行わせるための技術のことである。情報の意味(Semantics)をコンピュータ自身に理解させることで、人を仲立ちさせることなく情報のやりとりを行わせることができる。WWW関連技術の創始者であるティム・バーナーズ・リーによって提唱された。
よくわかりません。
とりあえず、WWW関連の中枢部が提唱している、WEBの効率化、よりユーザーフレンドリーなコンテンツの提供のために連携を強める、とっても大事なことなんです。
構造化データ とは
HTMLの要素が含むテキスト、そのHTML構造の意味を検索エンジンに対して明示的にすることを指します。
それぞれの役目を、コードを追記することで検索エンジンに教えてあげるということですね。
HTMLを構造化するメリットは
検索結果でこのようにレビューなどが表示されることがあります。

通常、meta descriptionで記述した内容が表示されますが(勝手に気の利いた抜粋をしてくれる例もあるらしい)
構造化を正しく行いHTMLの存在をクローラに伝えることで、上記の例だとレビューの★がでたり価格が表示されたりと…
ユーザーの需要によりマッチした検索結果として表示されるのです。つまりはクリックに有効に働きかけることが出来るのです!
こういった行いを「セマンティックSEO」なんて言ったりしますね。
細かく言うともっと別の定義があるだのSEOとは言えねーとかありますが僕はSEO担当ではないので黙って続けます
2つのキーワード「ボキャブラリー」と「シンタックス」
この2つが重要になってきます。
まずは「ボキャブラリー」。これは構造化を行う上での「規格」(大枠)のようなものです。
Google , Yahoo! , Microsoftが共同で開発しているschema.orgが有名です。
次に「シンタックス」。こちらは定義する「値」だとか「名前」(小枠)のことです。
- Microdata
- RDFa
- Microformats
- JSON-LD
がありますが、Googleが推すのは「Microdata」です。
これら、ボキャブラリーとシンタックスをHTMLに記述して構造を明示します。
今回はschema.orgとmicrodataの組み合わせで解説していきます。
例として、ブログの名前とディスクリプションの構造化データをマークアップしてみます!
ツーブロッカ
一年中ツーブロックのWebデザイナーが書くブログ
簡単に書くとこんな感じでしょうか…(間違っていたら教えて下さい)
では記述の説明をしていきます。
itemscope
これを書いた要素を基準として、「内包されているHTMLが何かについて語っているよっと!」と話し始める役割をします。。
構造化データを付与していく、ということになります。
itemtype
itemscopeと同じHTMLに、半角スペースを空けて続けて書きます。
これは、「内包されているHTMLは、●●について語っているんだよ!」と示すためのものです。
例の場合だと、http://schema.org/WebPageです。
「内包しているHTMLはschema.orgボキャブラリのWebpageという小枠のなかのことだよー」と示しています。
itemprop
itemtypeにもとづき、その子要素にあたるHTMLの役割を明示的にします。名札を貼る的な感じでしょうかね
例の場合、「Webpage」の子要素である
ツーブロッカ
は、当ブログの名前を表す部分ですので、
「
ツーブロッカ
」
となります。続けて、当ブログについて語っている、いわば「ディスクリプション」的な部分は、
一年中ツーブロックのWebデザイナーが書くブログ
「about」いう名札を貼って、わかりやすくしてあげます。
しかしなんでもいいというわけではなく、これらは全て、ボキャブラリーであるschema.orgのwebサイトに丁寧に階層分けし、記載されています。
この規則にのっとり、WebPageの中のnameはここだ、aboutはここだ、と割り振っていくのです。
ではこのサイトの見方を軽く紹介します。
schema.orgの見方を簡単に説明
http://schema-ja.appspot.com/docs/schemas.html
ここではトップページにあまり用はないので、上記にアクセスしましょう。
「1ページに全ての型をリストで表示」をクリックします。すると、
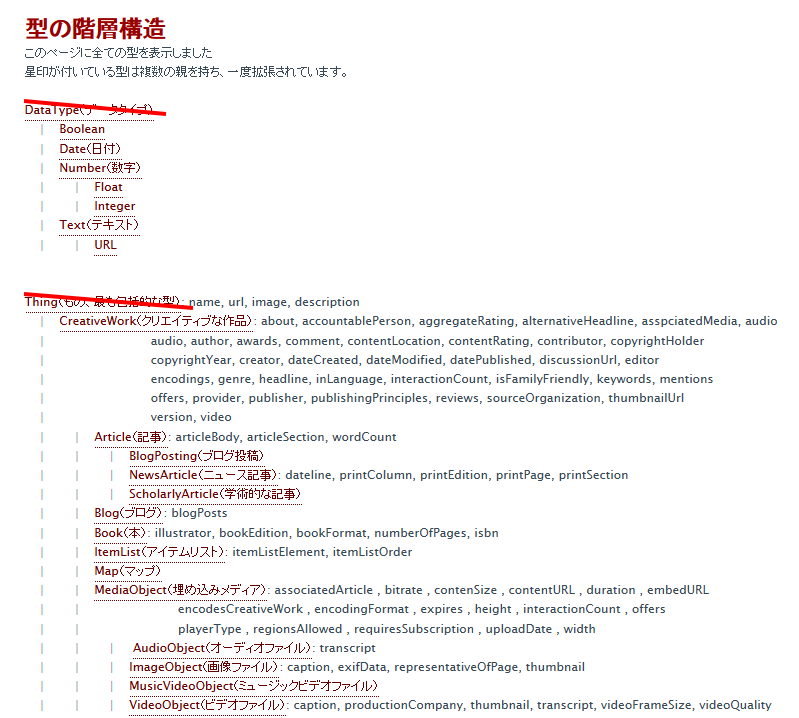
このように列挙された画面になりますが、一番左のDatatypeやThingは、ひとまず無視してください。
その右にある「Creative Work」や「Blog」の縦列が、「itemtype=”http://schema.org/★★”」の★の部分に記述して
「どんなジャンルに対して意味をつけていくか」の定義をする語句です。
では、例になぞらえるために、下にスクロールして見えてくる「WebPage」をクリックします。
見づらいですが、このような画面になっているかと思います。ここがシンタックスのページです。
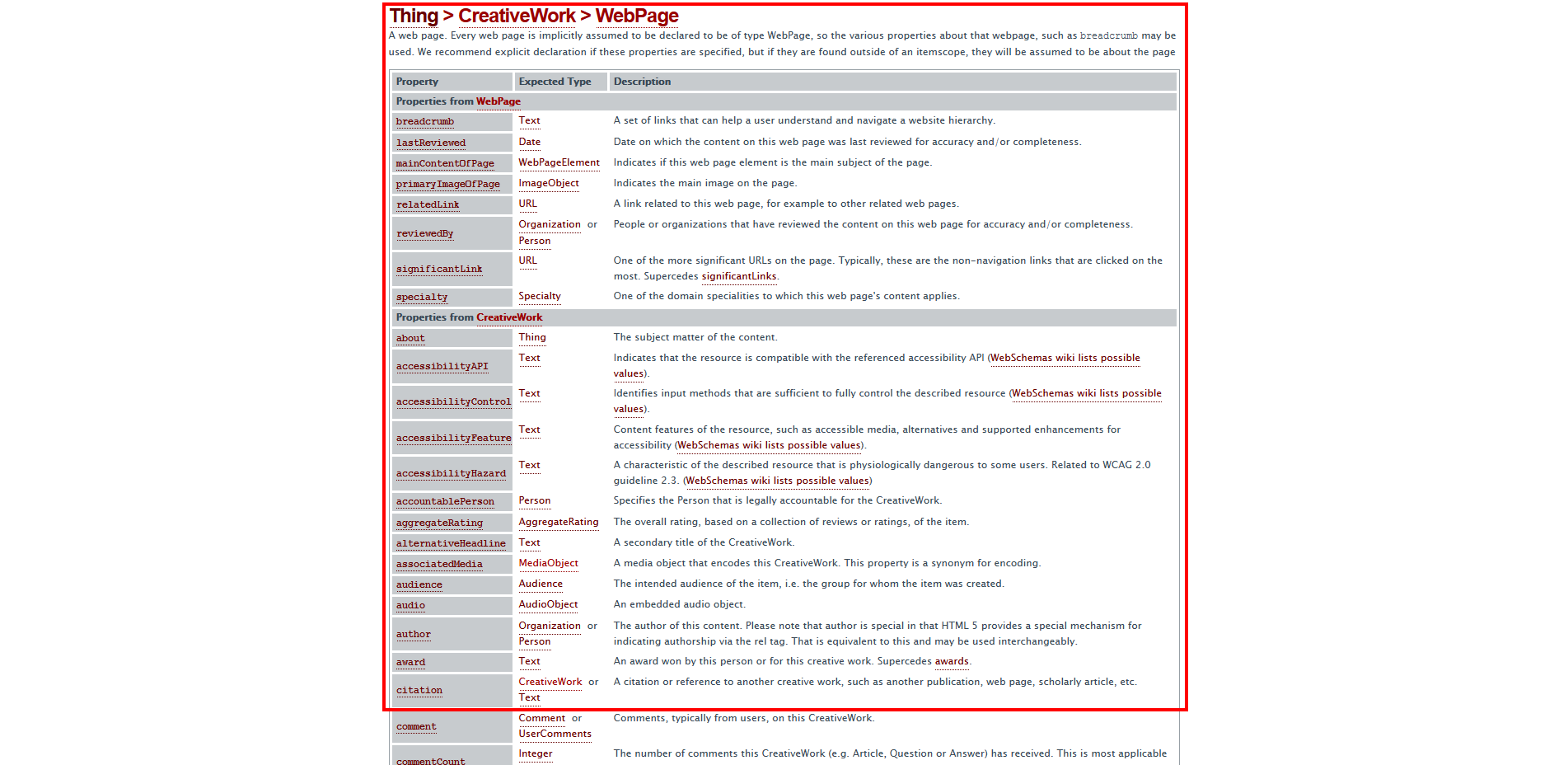
左側の背景が灰色になっている列が、「itemprop=”★★”」の★の箇所に指定することができる語句です。
今見ているところは「WebPage」のシンタックスなので、「itemtype=”http://schema.org/WebPage”」が親であることが条件になります。
よく解らないという方は、下にスクロールすると「Example」という見出しの下にサンプルコードがあります。
「Microdata」タブをクリックしてください。
......The Catcher in the Rye - Mass Market Paperback by J.D. Salinger
4 stars - 3077 reviewsPrice: $6.99 In StockProduct details 224 pages Publisher: Little, Brown, and Company - May 1, 1991 Language: English ISBN-10: 0316769487 Reviews:5 stars - "A masterpiece of literature" by John Doe, Written on May 4, 2006 I really enjoyed this book. It captures the essential challenge people face as they try make sense of their lives and grow to adulthood.4 stars - "A good read." by Bob Smith, Written on June 15, 2006 Catcher in the Rye is a fun book. It's a good book to read.

「」の中に、「
更にこの中には、パンくずリストが書かれているため、クローラにはこの部分がパンくずリスト(breadcrumb)だ、と認識してもらえるわけです。
ちなみに、構造化データマークアップをする上で、それぞれを「入れ子」にすることが出来ます。
上記の場合だと、
4 stars - 3077 reviewsPrice: $6.99 In StockProduct details 224 pages Publisher: Little, Brown, and Company - May 1, 1991 Language: English ISBN-10: 0316769487 Reviews:5 stars - "A masterpiece of literature" by John Doe, Written on May 4, 2006 I really enjoyed this book. It captures the essential challenge people face as they try make sense of their lives and grow to adulthood.4 stars - "A good read." by Bob Smith, Written on June 15, 2006 Catcher in the Rye is a fun book. It's a good book to read.
この部分です。「
「WebPage」の中で、ある部分を適切に表現するために「Book」入れ子にしているのですね!
例外:1つのitempropが、itemscopeの役割も果たす場合
もう何が何だかワケが解りませんが、こういう状況下である場合があります。
当ブログの例に戻りますね。
ツーブロッカ
一年中ツーブロックのWebデザイナーが書くブログ
ここに、著者である僕の名前を入れましょう。ついでに、僕の個人情報的なのも載せましょう。
ツーブロッカ
一年中ツーブロックのWebデザイナーが書くブログ
の中に僕の名前と誕生日を入れました。
ここは「WebPage」の「著者(author)」について書いていますが、
「著者(author)」は、「人」であり、「人(Person)」というのは名前や誕生日といった別の情報も持っています。
誕生日や名前などを記載した場合、誕生日を書いているHTMLにも
「”誕生日(birthDate)”という役目を担っている」、と名札を貼ります。
そして誕生日、名前の親要素である、例で言うasideにも
「 itemscope itemtype=”http://schema.org/Person”」を記述します。
「このエリアは著者という”人”の情報です」と示すのです。
ツーブロッカ
一年中ツーブロックのWebデザイナーが書くブログ
実際に、自分のWebサイトを構造化データーマークアップしたい!
正直な話、イメージが湧きづらいと思います…
僕もschema.orgをチラ見しながら試してみましたが、正しく出来ているか解りません。
クローラーが巡回してきて結果がでるのだろうか…
とりあえずコーディングまでは済ませたい!イメージだけでも掴みたい!という方は、Googleが提供するサービスがオススメです。
ラジオボタンで、自分のWebサイトのジャンルとして近いものを選択し、URLを入力します。
ブログの場合は「記事」ですね。
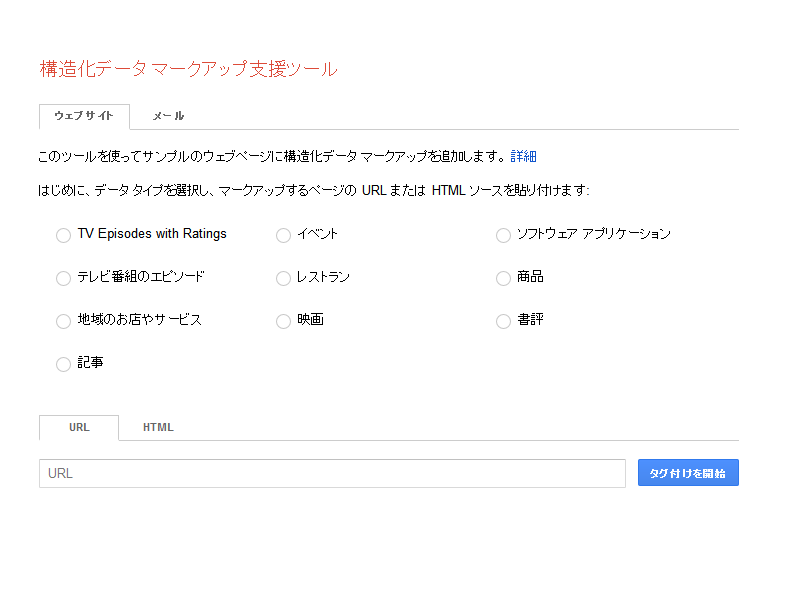
「タグ付けを開始」をクリックするとサイトの読み込みが始まります
サイトが表示されたら、試しに記事のタイトル部分をドラッグしてください。
現れるメニューから「名前」を選びます。
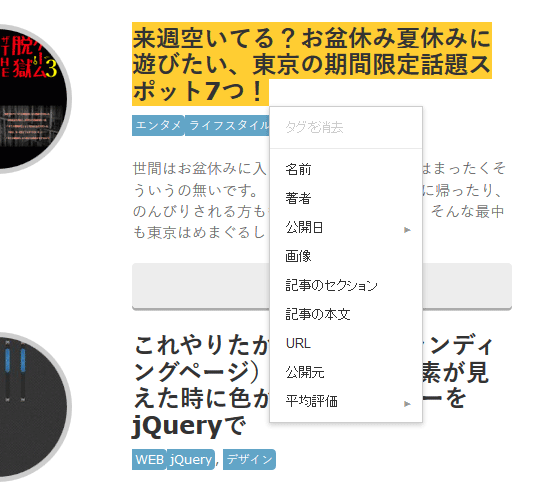
次に、サムネイル部分をクリック。同じように現れるメニューでこんどは「画像」を選びます。
ここまでで、その記事のタイトルとサムネイルが認識されていると思いまsy。
画面右側のこの部分を見て

上手く当てはめていってください。
キリのいいところで、「HTMLを作成」をクリック。
するとサイトのHTMLに、画面で当てはめた構造化データが反映された状態で表示されます。
ここで完璧に実現はしきれなと思いますが(デザインと色々都合がアレで)なんとなく、itemtypeとitempropの関係を知るにはいいでしょうね。
ここまでざっと基礎的な部分を説明しました。
おそらく続編をメモしていくと思いますので、続けて目を通していただければ幸いです!
でわ!















